異地雙活數(shù)據(jù)庫實(shí)戰(zhàn)

主要圍繞以下五點(diǎn)進(jìn)行分享:
- 多活當(dāng)中的難點(diǎn)
- 多活的架構(gòu)
- 數(shù)據(jù)庫改造
- DBA 挑戰(zhàn)
- 收益與展望
多活當(dāng)中的難點(diǎn)
我們先來看一下多活的第一個(gè)難點(diǎn):要考慮做多活到底是同城的多活還是異地的多活。
跨地域網(wǎng)絡(luò)延時(shí)是現(xiàn)階段很難突破的點(diǎn),因?yàn)轲I了么面臨的是異地的多活,所以我們需要基于延時(shí)這個(gè)前提來考慮方案。
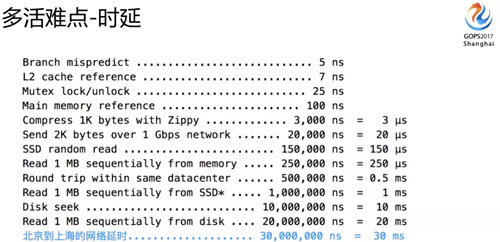
從北京到上海中間有 30 毫秒的延遲,這個(gè)會(huì)帶來什么問題?我們接下來會(huì)講。
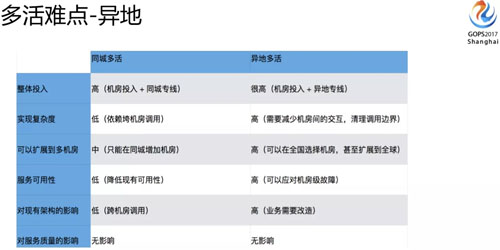
上圖是同城和異地多活不同的點(diǎn),復(fù)雜性和可拓展性對(duì)架構(gòu)的影響方面會(huì)有很大的不同。
我們挑幾個(gè)點(diǎn)講一下:
- 如果只是做同城多活的話,像 30 毫秒的延時(shí)不需要考慮,因?yàn)橥堑难訒r(shí)通常只有幾毫秒,跟同機(jī)房相差不大。
- 如果是異地 30 毫秒的延時(shí)就需要重點(diǎn)考慮了,因?yàn)槿绻欠磸?fù)調(diào)用的應(yīng)用,放大的時(shí)間就不只是 30 毫秒了,可能是 300 毫秒、500 毫秒,對(duì)很多應(yīng)用來說是不可接受的。
在可擴(kuò)展性方面如果做的是異地多活的話,你的可擴(kuò)展性理論上來說沒有太多的邊界。
我們做同城多活只能在上海機(jī)房里面選,如果是異地多活,可能是全國(guó)甚至是全球都可以選。

還有一個(gè)比較難的問題,就是怎么保證數(shù)據(jù)的安全?多活數(shù)據(jù)可能面臨多個(gè)寫入點(diǎn),可能會(huì)錯(cuò)亂、會(huì)沖突、循環(huán)復(fù)制、數(shù)據(jù)環(huán)路等問題。
這種情況下怎么保障一致性?如果這些沒有考慮好之前,你是不能上多活方案的,多點(diǎn)寫入的風(fēng)險(xiǎn)對(duì)數(shù)據(jù)的考驗(yàn)是很大的。
綜合考慮下來我們選擇了異地多活,所以這些問題我們都需要克服,也意味著會(huì)面臨很多的系統(tǒng)改造。

如何解決跨機(jī)房延時(shí)對(duì)業(yè)務(wù)的影響,包括各種抖動(dòng)甚至是斷網(wǎng)的問題;怎樣有效區(qū)分我們?cè)L問的流量,最大限度地保障用戶的訪問落在正確的機(jī)房,這個(gè)都是需要解決的難點(diǎn)。

我們采取了一些措施,如上圖:
盡量把業(yè)務(wù)做成類聚的,讓一個(gè)用戶的訪問落在同一個(gè)地方。不是所有的業(yè)務(wù)都有多活特性的,還可以有全局使用的業(yè)務(wù)(比方用戶數(shù)據(jù)),所以需要做業(yè)務(wù)類型劃分。
在服務(wù)劃分這一層,怎么定義業(yè)務(wù)調(diào)用的邊界,還有我們基于什么對(duì)流量和用戶做劃分的呢?
目前根據(jù)我們的業(yè)務(wù)特點(diǎn)使用的是地理圍欄(POI),用戶、商戶、騎手當(dāng)前所在的地理位置是我們?nèi)肟诹髁縿澐值囊罁?jù)。
再看看路由控制這一塊,除了入口流量這一層做了機(jī)房的劃分,還在內(nèi)部使用了虛擬的 Shardingkey,ShardingKey 會(huì)把全國(guó)流量分成多個(gè)部分,并且與 POI 標(biāo)簽綁定。
這樣就可以把邏輯 ShardingKey 和物理位置對(duì)應(yīng)起來,切換的時(shí)候訪問就可以隨 ShardingKey 分流到不同的機(jī)房。
APIRouter 就是為了完成這個(gè)工作的,它會(huì)根據(jù)配置的規(guī)則把 Shardingkey 對(duì)應(yīng)的流量分到對(duì)應(yīng)的機(jī)房。
臟寫預(yù)防方面,為防止數(shù)據(jù)沖突,我們也需要業(yè)務(wù)配合做一些多活規(guī)則的改造,這些規(guī)則對(duì)業(yè)務(wù)還是有一些侵入性的。
另外 SOA-Route 就是內(nèi)部跨業(yè)務(wù)調(diào)用的訪問路由;還有一個(gè) DAL,就是數(shù)據(jù)庫的代理層。
業(yè)務(wù)訪問在我們多層的路由控制下,理論上應(yīng)該能正確路由到合適的機(jī)房,如果超越規(guī)則或者沒有按規(guī)則改造的意外流量真正穿透到 DAL 這一層的時(shí)候我們是強(qiáng)制拒絕的。
因?yàn)榈讓诱J(rèn)為這個(gè)訪問是屬于異常的調(diào)用,流量走錯(cuò)了機(jī)房,這時(shí)候就會(huì)拒絕,所以我們寧愿讓他失敗也不能讓控制之外的數(shù)據(jù)進(jìn)來,這樣才能保障規(guī)則和數(shù)據(jù)的可控性。
數(shù)據(jù)一致性方面,我們有一個(gè)重要的 DRC 數(shù)據(jù)同步組件,數(shù)據(jù)庫這塊有一些自增的控制,DBA 還研發(fā)了一個(gè)數(shù)據(jù)一致性校驗(yàn)的工具。
多活的架構(gòu)
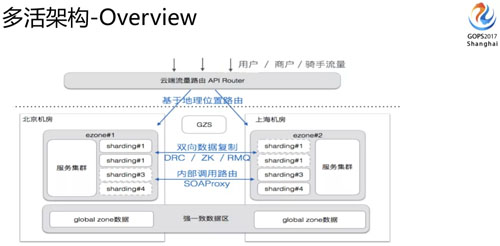
粗略說了一些多活的難點(diǎn)和我們的應(yīng)對(duì)方案后,我們現(xiàn)在來看一下整個(gè)多活的架構(gòu)。
如上圖,最上面是我們從入口流量、分流控制、數(shù)據(jù)多機(jī)房同步,包括各個(gè)重要組件的架構(gòu)等。
還有里面有 globol zone 這一項(xiàng),它是我們剛剛講的需要全局依賴的業(yè)務(wù)會(huì)把它放在 globol zone 里面。
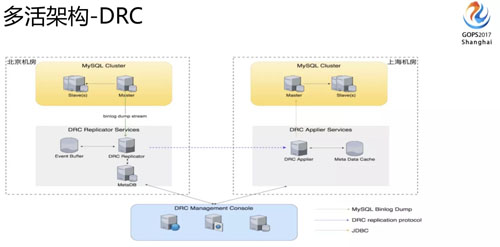
DRC 這是做多活時(shí)相當(dāng)重要的組件,主要解決數(shù)據(jù)在多個(gè)機(jī)房當(dāng)中的同步復(fù)制。
我們從北京機(jī)房寫入的數(shù)據(jù),會(huì)同步到上海的機(jī)房,上海的機(jī)房寫入的數(shù)據(jù)也會(huì)通過 DRC 這個(gè)組件同步到北京的機(jī)房。
大家可以看到,它包含三塊服務(wù),Replicator、Applier 和 Manager。一個(gè)收集變更數(shù)據(jù)、一個(gè)將變更數(shù)據(jù)寫入到另一個(gè)機(jī)房、另外一個(gè)是做管理控制。
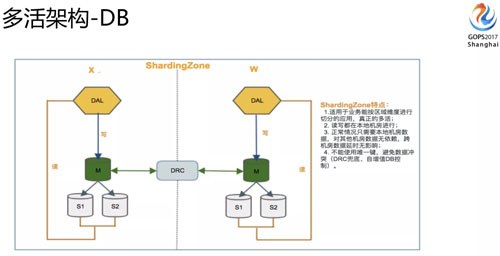
DB 架構(gòu)這塊我們有兩類(準(zhǔn)確講還有一類是多推的,比較少):
- 第一類是 Sharding Zone,不管是數(shù)據(jù)寫入還是訪問都是本機(jī)房提供,出問題的時(shí)候也只是流量的切換,并不涉及到底層的變動(dòng),這個(gè)是真正多活的架構(gòu)。
- 還有一種是剛剛講的 globol zone,有些沒有辦法做業(yè)務(wù)分區(qū),因?yàn)槭?globol zone 的架構(gòu),寫入是集中在一個(gè)機(jī)房,讀取在本地機(jī)房完成。
大家可能會(huì)想到 global zone 這種架構(gòu)會(huì)天然面臨一些數(shù)據(jù)延遲的問題,所以這塊我們的定義是一些寫入量不大,訪問量大,對(duì)數(shù)據(jù)延時(shí)是不那么敏感的業(yè)務(wù)就可以放到這里面來。
數(shù)據(jù)庫改造
多活項(xiàng)目我們調(diào)研大概花的時(shí)間有半年左右,但真正做改造的時(shí)候時(shí)間是相當(dāng)短的。
從啟動(dòng)這個(gè)項(xiàng)目到真正上線就用了三個(gè)月左右的時(shí)間,那時(shí)候時(shí)間是相當(dāng)緊的,大家可以看一下我列舉的為配合多活數(shù)據(jù)庫所做的大的改造項(xiàng)目。
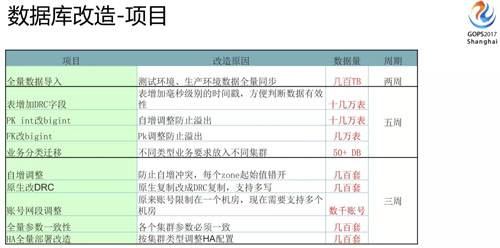
首先面臨的問題,就是我們要把數(shù)據(jù)全量的從一個(gè)機(jī)房導(dǎo)入到另外一個(gè)機(jī)房,這個(gè)不光有測(cè)試環(huán)境還有生產(chǎn)環(huán)境都要全量的同步。
我們數(shù)據(jù)有幾百 T 數(shù)據(jù),幾百套集群,有各種主從結(jié)構(gòu)需要搭建,每個(gè)節(jié)點(diǎn)時(shí)間也很短。
我們剛剛講的 DRC 會(huì)做數(shù)據(jù)的同步,但同步的時(shí)候也會(huì)面臨數(shù)據(jù)沖突的問題。
為解決這個(gè)問題,我們需要在所有表上增加一個(gè) DRC 時(shí)間戳字段,用來判斷哪一邊數(shù)據(jù)是最新的,這樣在數(shù)據(jù)發(fā)生沖突的時(shí)候,我們會(huì)選最新的數(shù)據(jù)作為最終的數(shù)據(jù)。
為防止多活主鍵沖突,數(shù)據(jù)庫做了一些自增的調(diào)整,自增步長(zhǎng)放大后馬上就會(huì)面臨數(shù)據(jù)溢出的問題,所以我們需要把主鍵都從 int 調(diào)整為 bigint。
主鍵改完以后還有一些外鍵依賴的也會(huì)需要改造,所以整體會(huì)要做很多的 DDL(幾乎是全量表),而在 MySQL 里面 DDL 其實(shí)是風(fēng)險(xiǎn)比較高的操作。
第二個(gè)大改造是因?yàn)閰^(qū)分了不同的業(yè)務(wù)類型(我們剛剛講了有 golobl zone 這些),就會(huì)面臨各種不同類型的業(yè)務(wù)原來在同一套實(shí)例上的情況。
現(xiàn)在需要拆分遷移到不同的實(shí)例上,這個(gè)我們也陸陸續(xù)續(xù)遷移 50+ 的 DB,現(xiàn)在還有些在遷移。
下一個(gè)改造是我們現(xiàn)在用 DRC 做跨機(jī)房的數(shù)據(jù)同步了,所有的數(shù)據(jù)同步都是原生的改成 DRC 的模式,也會(huì)做很多的調(diào)整。
還有一個(gè)問題,就是帳號(hào)網(wǎng)段也需要做調(diào)整,因?yàn)槲覀冊(cè)瓉砘诎踩紤]會(huì)限制某些 IP 網(wǎng)段,現(xiàn)在網(wǎng)段范圍放大了,所有帳號(hào)都要面臨調(diào)整網(wǎng)段的問題。
如果量比較多的話,調(diào)整賬號(hào)風(fēng)險(xiǎn)還是挺高的(很多歷史遺漏會(huì)使得主從賬號(hào)不一致,出現(xiàn)同名賬號(hào)不同網(wǎng)段等問題,如果出現(xiàn)不一致調(diào)整的時(shí)候主從會(huì)中斷)。
另外怎么保證全局參數(shù)的一致性,起碼要保證同一個(gè)集群,在各個(gè)機(jī)房參數(shù)都是一致的,這個(gè)是比較臟活累活的東西,但是很容易出問題,到處是坑。
另外 HA 也面臨改造,因?yàn)樵瓉碓谝粋€(gè)機(jī)房,現(xiàn)在有多個(gè)機(jī)房,怎么做到 HA 的可靠性也是一個(gè)問題,這塊我們也做了很多的改造。
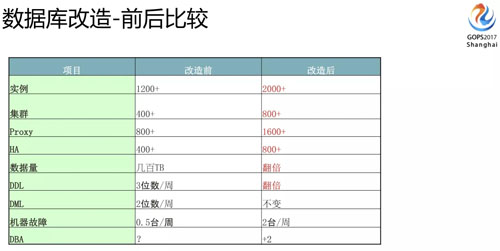
改造完成之后,我們對(duì)比下改造前后在數(shù)據(jù)庫這端的變化。實(shí)例就翻了一倍,集群數(shù)量、Proxy 配置、數(shù)據(jù)量、HA 都會(huì)翻倍。
這里特別列了一些 DDL 的變化,為什么會(huì)有變化?因?yàn)?DRC 不做 DDL 同步這個(gè)事情,這個(gè)事情都需要 DBA 分開機(jī)房來做。
機(jī)器故障每周也增加了,原來一周碰不到一臺(tái),現(xiàn)在可能一周面臨兩到三臺(tái)這樣的機(jī)器故障,所以必須要保證你的 HA 是足夠可靠的。
但是我們?nèi)藬?shù)是沒怎么增加,而且我們馬上要上第三個(gè) zone,維護(hù)的工作量會(huì)增加更多。
不過我們沒有加人的計(jì)劃,之所以這樣是因?yàn)槲覀冊(cè)诎押芏嗟墓ぷ魍ㄟ^平臺(tái)、自動(dòng)化和項(xiàng)目的方式來推動(dòng)解決掉。
DBA 挑戰(zhàn)

對(duì) DBA 來講,除了業(yè)務(wù)在多活的時(shí)候做改造,架構(gòu)在多活時(shí)候的支持外,我覺得做多活改動(dòng)最大的就是 DBA 了,對(duì) DBA 的挑戰(zhàn)很大。
就像前面說的,在集群數(shù)量很大的情況下,怎么有效保障數(shù)據(jù)一致性、HA、配置、容量,還有 DDL 等問題。
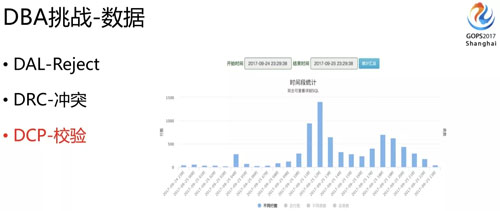
我們可以看一下,剛剛講數(shù)據(jù)這塊我們需要保證它不能錯(cuò)、不能亂,也不能說因?yàn)橛幸恍?shù)據(jù)的沖突,我們整個(gè)的數(shù)據(jù)流就停下來,這也不合理,否則多活就沒有意義了。
再一個(gè),即便是把前面流量的東西,都按規(guī)則走了,但你也不能保證各個(gè)組件不會(huì)出一些 Bug 的問題。
比如說 DRC 同步的時(shí)候就有 Bug,我們就要有兜底的檢測(cè),把有問題的數(shù)據(jù)及時(shí)的發(fā)現(xiàn),甚至是修復(fù)好。
所以我們 DBA 研發(fā)了一個(gè) DCP 的平臺(tái)。
DCP 就是為數(shù)據(jù)一致性兜底的,它會(huì)全量的對(duì)比我們各個(gè)機(jī)房的數(shù)據(jù),告訴 DBA 到底什么時(shí)候有數(shù)據(jù)不一致的問題,大概是多少,是什么樣的類型,怎么修復(fù),不一致量大的時(shí)候還需要有合適的修復(fù)工具。
對(duì) DCP 設(shè)計(jì)來說,因?yàn)槲覀冇泻芏嗵准海儎?dòng)很多,如果說一旦變動(dòng)就要人為調(diào)整的話,這個(gè)維護(hù)量也是很大的,也很難保證它的準(zhǔn)確無誤。
所以它必須能自適配,它需要支持全量、增量、延時(shí)的控制校驗(yàn)和隨時(shí)手動(dòng)校驗(yàn)。
延時(shí)校驗(yàn)就是我們有時(shí)候跨機(jī)房的時(shí)候天然就面臨延時(shí),這時(shí)候如果有延時(shí)數(shù)據(jù)肯定有差異,DCP 需要知道到底是因?yàn)檠訒r(shí)導(dǎo)致的數(shù)據(jù)不一致還是數(shù)據(jù)真的不一致。
還有黑白名單機(jī)制,自定義規(guī)則,白名單有一些表我們不需要校驗(yàn)就可以跳過。自定義規(guī)則就是可以設(shè)定一些相應(yīng)的過濾條件來比較,濾掉一些不需要比較的數(shù)據(jù)。
DCP 不光是支持對(duì)數(shù)據(jù)一致性的校驗(yàn),表結(jié)構(gòu)不一致了也需要校驗(yàn),甚至說多維數(shù)據(jù)也能提供校驗(yàn)支持。
比如說一個(gè)訂單可能根據(jù)用戶做了拆分,也根據(jù)商戶做了拆分,這兩個(gè)數(shù)據(jù)是否一致是需要校驗(yàn)的。
還有我們需要控制比較的是它的延時(shí)、并發(fā)、校驗(yàn)的時(shí)長(zhǎng)等,因?yàn)槟愕男r?yàn)一直在跑,消耗過大,跑的時(shí)間很長(zhǎng)勢(shì)必對(duì)生產(chǎn)會(huì)造成影響。
最后我們是需要提供靈活修復(fù)的工具和配套的腳本。
這樣比出來的數(shù)據(jù)才能夠快速的恢復(fù),否則你雖然知道數(shù)據(jù)有問題,但要找這些數(shù)據(jù)怎么樣不一致的,怎么去修復(fù),再根據(jù)條件去把腳本寫出來,這個(gè)過程就很長(zhǎng)了,等你修復(fù)說不定業(yè)務(wù)已經(jīng)影響比較大了。

DCP 平臺(tái)上線以后,每天大概有 400 多套集群需要校驗(yàn),日均校驗(yàn)的數(shù)據(jù)有 60 多億,分鐘級(jí)別的校驗(yàn)頻率。實(shí)際發(fā)現(xiàn)數(shù)據(jù)一致性的問題起碼有 50+ 例。
不一致的原因可能是業(yè)務(wù)寫錯(cuò)了,DRC 出 Bug 了,還有可能是各環(huán)節(jié)(包括 DB)的配置問題。
如果你沒有相應(yīng)數(shù)據(jù)校驗(yàn)的工具,你是很難知道到底數(shù)據(jù)是不是一致的,多活做的時(shí)候這個(gè)情況必須要能掌握,否則心里沒底了。
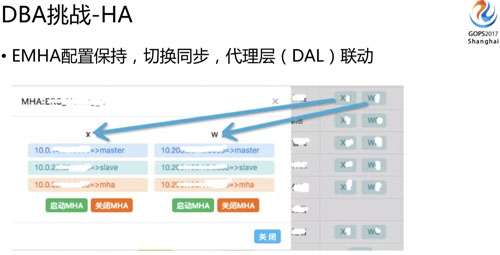
剛剛講的是數(shù)據(jù)校驗(yàn) DCP 的平臺(tái),還有一個(gè) HA 的保障,集群數(shù)量翻番了,這時(shí)候你需要保證任何一個(gè)節(jié)點(diǎn)掛了都能盡快的切過去。
同時(shí),如果你的節(jié)點(diǎn)有調(diào)整有下線等,你都需要保證 HA 配置能夠跟著變動(dòng),否則 HA 的成功率就會(huì)得不到保證,800 多套集群也不可能再依賴人肉去保證了。
所以我們做了一個(gè) EMHA,它有什么作用呢?
首先集群任何節(jié)點(diǎn)變動(dòng)都能夠自動(dòng)感知,當(dāng)然我們底層是依賴于 MHA 的,MHA 的配置大家用過的話都知道它需要對(duì) SSH 做互通。
有任何一個(gè)調(diào)整需要把它從配置文件里面加進(jìn)去或者刪除,否則切換就有問題,所以 EMHA 新增了自動(dòng)感知配置保持的功能,自動(dòng)解決這些問題。
第二個(gè)重要的功能是變動(dòng)信息的擴(kuò)散通知的機(jī)制,因?yàn)槲覀兪峭ㄟ^ DRC 同步數(shù)據(jù)的。
如果有一個(gè) master 出問題切換了,這時(shí)候要通知 DRC 去連新的 master,并且還需要提供相應(yīng)的位點(diǎn)信息,還有各種監(jiān)控也需要得到通知。
要知道這個(gè) master 掛了以后,新的 master 是哪一個(gè),否則后面維護(hù)的信息都會(huì)錯(cuò)亂。
第三點(diǎn)我們的切換需要讓 Proxy 這一層自動(dòng)感知,如果不能自動(dòng)感知的話,每次切換 Proxy 都需要維護(hù),這個(gè)可能會(huì)中斷生產(chǎn)的訪問,而且這個(gè)維護(hù)質(zhì)量基本也得不到保證,所以 EMHA 也會(huì)自動(dòng)完成與 Porxy 配置層信息的互通。

還有配置的保持也是比較麻煩的事情,我們?cè)诖韺拥呐渲茫绻?jié)點(diǎn)變動(dòng)了也需要變(調(diào)整區(qū)別于切換,切換 DAL 可以通過 EMAH 自動(dòng)感知)。
有各種參數(shù),如果說調(diào)整不一樣了,也需要全局的同步的,這些東西都需要有很多自動(dòng)發(fā)現(xiàn)的手段,包括自動(dòng)處理的方式。
當(dāng)然我們現(xiàn)在有些也還沒能完成做到自動(dòng)化(正在努力中),目前還有些是通過巡檢腳本來發(fā)現(xiàn)的,起碼保證能夠發(fā)現(xiàn)它然后解決掉。
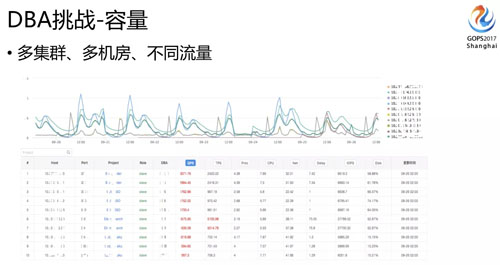
容量這塊,現(xiàn)在是兩個(gè)機(jī)房,兩個(gè)機(jī)房的流量并不一定均衡,比如上海機(jī)房 70% 的流量,北京機(jī)房 30% 的流量,但流量會(huì)隨時(shí)切換,所以必須保證每個(gè)機(jī)房都能夠承擔(dān)所有流量。
當(dāng)然三個(gè)機(jī)房的話,不一定百分之百的冗余,但也一定要知道每套集群是不是能承載切換過來的流量,否則切換過來就面臨雪崩的效應(yīng)。
所以對(duì)各項(xiàng)指標(biāo)我們都要有相應(yīng)的水位監(jiān)控,提前發(fā)現(xiàn)這些問題。
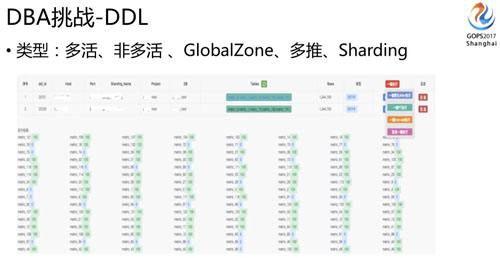
還有一個(gè)很大的困難是在 DDL 這塊,因?yàn)?DRC 里面不方便做 DDL 這個(gè)事情,之前我們也嘗試讓 DRC 同步 DDL 操作。
比如說我們做 DDL 的時(shí)候,一般是用 PT 工具來做,這個(gè)過程要拷貝整張表的數(shù)據(jù)。
如果這個(gè)表比較大,DDL 時(shí)兩個(gè)機(jī)房之間的流量就會(huì)面臨很大的沖擊,而且延時(shí)會(huì)相當(dāng)大。
比如說 100G 的表在一個(gè)機(jī)房做完要同步到另外一個(gè)機(jī)房去,這沖擊業(yè)務(wù)影響是不可接受的。
所以 DDL 需要 DBA 在每個(gè)機(jī)房單獨(dú)做,我們開發(fā)了一套 DDL 發(fā)布工具,因?yàn)槲覀冇泻芏鄶?shù)據(jù)類型,有 global zone,還有 Sharding Zone,我們還有大量 Sharding 表。
對(duì)單個(gè)業(yè)務(wù)邏輯表的 DDL 來說,實(shí)際上我們一套集群里面有幾百張表,這個(gè)表又分布在多套集群里面。
所以實(shí)際業(yè)務(wù)一張邏輯表的 DDL 操作,實(shí)際 DDL 需要做一千張表,同時(shí)還有各種不同的業(yè)務(wù)集群類型,我們?cè)诎l(fā)布工具時(shí)必須要能自動(dòng)適配和識(shí)別這些情況(這個(gè)時(shí)候元數(shù)據(jù)維護(hù)相當(dāng)重要了,因?yàn)槿艘呀?jīng)識(shí)別不了啦,只能依靠工具)。
剛剛講 DDL 的時(shí)候,大家普遍用 PT 的工具,我們用的時(shí)候也發(fā)現(xiàn)了很多問題,畢竟是它是同步觸發(fā)器的,一旦加上去之后,如果瞬間 TPS 很高,就會(huì)把數(shù)據(jù)庫打爆。
所以我們?cè)谶@塊也做了大量的改造,現(xiàn)在大部分情況下,我們已經(jīng)不用 PT 了,大家看這個(gè)圖上有好幾種工具可以選擇。
我們基于開源社區(qū)的 gh-ost 做了一個(gè)二次開發(fā)改造,改造后的工具叫 mm-ost。
它是一個(gè)跨機(jī)房的 DDL 工具,不僅解決了 DDL 的時(shí)候 threadrunning 不可控、主從延時(shí)不可控的問題,還解決了跨機(jī)房延時(shí)的問題,并且速度比 gh-ost 要快一倍。
我們是多機(jī)房,多機(jī)房和你做一個(gè)機(jī)房的 DDL 是完全不一樣的,因?yàn)槟愕臋C(jī)器可能有差異或者繁忙程度不一樣。
可能這個(gè)機(jī)房 DDL 做完了,另外一邊要半小時(shí)之后才能做完,尤其是一個(gè)業(yè)務(wù)邏輯表的 DDL 對(duì)應(yīng)的是上千張物理表的 DDL 時(shí),差異性就更大了。
這樣造成的跨機(jī)房延時(shí)業(yè)務(wù)可能沒法接受,所以我們需要的不僅是能保證同機(jī)房DDL主從延時(shí)的可控,還要保證跨機(jī)房延時(shí)的可控。
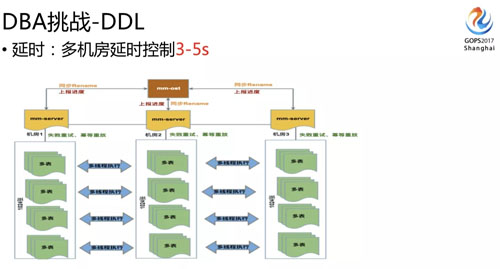
mm-ost 現(xiàn)在就能夠支持到跨機(jī)房同步完成 DDL 的時(shí)差控制在 3 到 5 秒之內(nèi)。
這延時(shí)對(duì)業(yè)務(wù)來說就沒什么感覺了,而且它可以支持暫停、探測(cè)到 DDL 數(shù)據(jù)延時(shí)的時(shí)候能夠減慢速度,能根據(jù)機(jī)器負(fù)載動(dòng)態(tài)調(diào)整 DDL 的速度等,所以現(xiàn)在 DDL 基本上對(duì)業(yè)務(wù)來說是沒有感覺的。
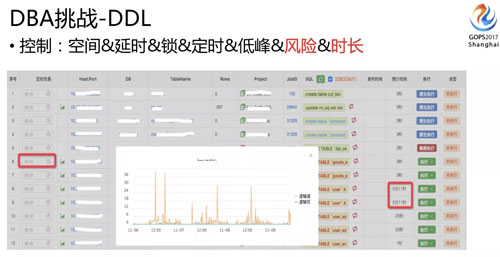
另外,大家可以看我們的發(fā)布平臺(tái)做的很復(fù)雜,它底層調(diào)用的是 mm-ost,在發(fā)布平臺(tái)上我們也做了很多控制。
比如說 DDL 空間滿不滿足,各個(gè)主機(jī)是不是都滿足去做 DDL 的條件,主從我們需要控制的延時(shí)在 30 秒之內(nèi),有鎖的時(shí)候需要減緩速度,還支持定時(shí)執(zhí)行。
因?yàn)槲覀冇行I(yè)務(wù)的低峰是晚上 4 點(diǎn),所以 DBA 不可能每次都是 4 點(diǎn)來做這個(gè)事情,這時(shí)就要定時(shí)功能的支持。
另外系統(tǒng)還可以通過識(shí)別業(yè)務(wù)高低峰推薦,什么時(shí)候做 DDL 比較合適,還有一些風(fēng)險(xiǎn)識(shí)別的控制,我們還要預(yù)估 DDL 的時(shí)長(zhǎng),如果開發(fā)問一個(gè) 500G 的表 DDL 大概多久能做完?
你需要大概告訴它,給它一個(gè)預(yù)期,總之發(fā)布這塊是我們面臨最大的一個(gè)挑戰(zhàn),我們?cè)谏厦孀隽撕芏喙ぷ鳌?/p>
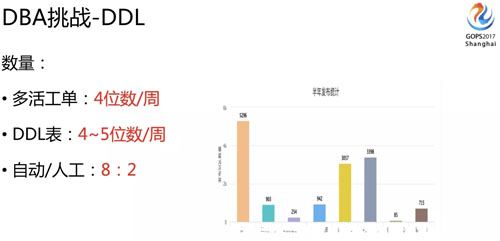
我們 DDL 數(shù)量相當(dāng)多,可以說在多活改造的時(shí)候,DBA 發(fā)布的量是最多的。
多活改造期間,我們 DDL 基本上每周的工單都在四位數(shù),四位數(shù)的工單數(shù)量,放到底層來講,可能一個(gè)邏輯表生成一千個(gè) DDL,就是最少是 5 位數(shù) DDL 物理表的量了。
如果完全依賴 DBA 來執(zhí)行,也很難支持了,所以我們加了自動(dòng)發(fā)布功能,對(duì)于風(fēng)險(xiǎn)不高的工單是系統(tǒng)自動(dòng)執(zhí)行的,粗略的比例大概是 8:2,絕大部分都是自動(dòng)發(fā)布了。
風(fēng)險(xiǎn)性比較高的工單我們才需要人去處理,我們統(tǒng)計(jì)了一下半年大概有 15000 個(gè)工單。
收益與展望

最后看一下多活做完以后收益有哪些?做多活之前,我們也面臨過很多棘手的問題:
- 比方我們之前面臨著整個(gè)機(jī)房出現(xiàn)問題(核心交換機(jī)出問題、網(wǎng)絡(luò)出問題)。
- 還有些機(jī)房因?yàn)樵跇I(yè)務(wù)沒有那么大之前你不可能預(yù)留特別多的機(jī)柜,但你現(xiàn)在說我業(yè)務(wù)漲的很快,現(xiàn)在要加一千臺(tái)機(jī)器、兩千臺(tái)機(jī)器的時(shí)候,發(fā)現(xiàn)你加不了,因?yàn)槟愕?IDC 不能給你這個(gè)支持,他們不可能給你預(yù)留這么多機(jī)柜。
這個(gè)時(shí)候你就面臨單機(jī)房沒法擴(kuò)容的麻煩,之前只能考慮遷移到一個(gè)更大的機(jī)房去,但也是個(gè)耗時(shí)費(fèi)力成本高的事情。
我們多活做了之后,首先打破了單機(jī)房容量的瓶頸,單機(jī)房不能擴(kuò)容的時(shí)候,我們現(xiàn)在可以在另外的機(jī)房擴(kuò)容我的機(jī)器,也可以分不同的流量來滿足負(fù)載,就不再受到單個(gè)機(jī)房容量的限制。
另一個(gè),多活上線到現(xiàn)在我們流量切了有 20 次左右,有時(shí)候是演練,有時(shí)候是真實(shí)發(fā)生故障。
現(xiàn)在就不再受到單機(jī)房故障的影響,甚至是單地域的影響,假如說上海哪一天全斷電了對(duì)我們影響也不大(當(dāng)然只是指技術(shù)層面)。
還有故障兜底,有的問題可能是比較麻煩的問題,一下子沒有辦法判斷或者解決,那時(shí)候可能影響很大,但只影響單個(gè)機(jī)房。
這個(gè)時(shí)候就可以把業(yè)務(wù)切到另外一個(gè)機(jī)房,等我們把問題解決了以后再把流量切回來,這樣對(duì)業(yè)務(wù)就基本沒有損失了,所以多活之后對(duì)我們整體可用性也有一個(gè)很大提升。
另外一塊是動(dòng)態(tài)調(diào)整各個(gè)機(jī)房的流量,尤其是在做一些促銷活動(dòng)的時(shí)候,有些地區(qū)的流量明顯是不均衡的。
這時(shí)候如果能動(dòng)態(tài)的調(diào)整機(jī)房之間的流量訪問,這是比較好的分擔(dān)壓力的方式,像阿里雙 11 這種活動(dòng),應(yīng)該會(huì)根據(jù)流量壓力來調(diào)整各機(jī)房之間的分配。

接下來在來講下多活這塊后續(xù)我們可能要做的一些事情:
一個(gè)是多個(gè)機(jī)房,我們現(xiàn)在正在準(zhǔn)備第三個(gè)機(jī)房,因?yàn)閮蓚€(gè)機(jī)房的代價(jià)比較高,冗余比較多。
我們需要做第三個(gè)機(jī)房分?jǐn)傔@塊的成本,當(dāng)然一開始成本是比較高的,往后業(yè)務(wù)繼續(xù)上漲的話,可能不需要做太多的擴(kuò)容。
而且現(xiàn)有百分之百冗余的機(jī)器資源,可以再做調(diào)配,這樣成本往后來看的話是會(huì)下降的。
另外一塊是數(shù)據(jù)的 Sharding,這個(gè)我們還沒有做到,因?yàn)槲覀冊(cè)诟鱾€(gè)機(jī)房都是全量的數(shù)據(jù),這也是我們后面努力的方向。
還有一個(gè)是自動(dòng)動(dòng)態(tài)擴(kuò)縮容,我們需要有更細(xì)的控制能力來自動(dòng)的完成這些動(dòng)作,尤其是在硬件資源利用率上能動(dòng)態(tài)調(diào)整。
最后一個(gè)點(diǎn)是希望能夠提供多機(jī)房數(shù)據(jù)強(qiáng)一致性的架構(gòu)方案,因?yàn)槲覀儸F(xiàn)在來講都是最終一致性的,怎么對(duì)一些非常重要的數(shù)據(jù),提供各個(gè)機(jī)房數(shù)據(jù)及時(shí)強(qiáng)一致性,這塊也是我們接下來需要努力的方向。
官方微信售電那點(diǎn)事兒")
責(zé)任編輯:售電衡衡
- 相關(guān)閱讀
- 碳交易
- 節(jié)能環(huán)保
- 電力法律
- 電力金融
- 綠色電力證書
-

碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè)
-
碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報(bào)告 | 基于分類監(jiān)管與當(dāng)量協(xié)同的碳市場(chǎng)框架設(shè)計(jì)方案
2020-07-21碳市場(chǎng),碳排放,碳交易 -

碳市場(chǎng)讓重慶能源轉(zhuǎn)型與經(jīng)濟(jì)發(fā)展并進(jìn)
2020-07-21碳市場(chǎng),碳排放,重慶
-
兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
2020年二季度福建省統(tǒng)調(diào)燃煤電廠節(jié)能減排信息披露
2020-07-21火電環(huán)保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -
我國(guó)能源替代規(guī)范法律問題研究(上)
2019-10-31能源替代規(guī)范法律 -

區(qū)域鏈結(jié)構(gòu)對(duì)于數(shù)據(jù)中心有什么影響?這個(gè)影響是好是壞呢!