深度:英特爾中國研究院吳甘沙談大數據

▲吳甘沙
我做了4-5年的移動架構和Java虛擬機,4-5年的眾核架構和并行編程系統,最近4-5年在追時髦,先是搞物聯網,最近幾年一直在做大數據。我們大數據的研究軌跡如下圖所示:前面2-3年主要是關注數據和機器的關系,水平擴展、容錯、一致性、軟硬件協同設計,還有就是厘清各種計算模式,從批處理(MapReduce)到流處理、Big SQL/ad hoc query、圖計算和機器學習。事實上我的團隊只是英特爾大數據研發力量的一部分,上海的團隊是英特爾Hadoop發行版的主力軍,因為英特爾成了Cloudera的最大股東,自己不做發行版了,但是平臺優化、開源支持和垂直領域的解決方案仍然是英特爾大數據研發的重心。
2013年開始看數據與人的關系,對于數據科學家怎么做好分布式機器學習、特征工程與非監督學習,對于領域專家來說怎么做好交互式分析工具,對于終端用戶怎么做好交互式可視化工具。英特爾研究院在美國CMU支持的科研中心做了GraphLab、Stale Synchronous Parallelism,在MIT的科研中心做了交互式可視化(真正做這個工作的教授在UW)和SciDB上的大數據分析,我們中國周邊主要做了Spark SQL和MLlib(機器學習庫)。現在也有涉及深度學習算法和基礎設施。
2014年開始看數據和數據的關系。

▲
為什么要琢磨數據和數據的關系呢?我們原來的工作重心是開源,后來發現開源只是開放式創新的一個部分,做大數據的開放式創新還要做數據的開放,大數據基礎設施的開放,以及價值提取能力的開放。
這是一張非常有意思的圖,黃色部分是化石級的、還沒有聯網、或者沒有數字化的數據,而絕大多數的數據是在這么一個海里面。只有海平面的這些數據(有的把它稱為Surface Web),才是真正大家能訪問到的數據,爬蟲能爬到、搜索引擎能檢索的數據,而絕大多數的數據是在暗黑之海里面(相應地叫做Dark Web,據說占數據總量的85%以上),在一些孤島里面,在一些企業、政府里面躺在地板上睡大覺。

▲
數據之于數據社會,就如同水之于城市或者血液之于身體。城市因為河流而誕生,也受其滋養,血液一旦流動停滯了,身體就有危險。所以,對于號稱數據化生存的社會來說,我們一定要讓數據流動起來,不然這個社會將會失去很多功能。
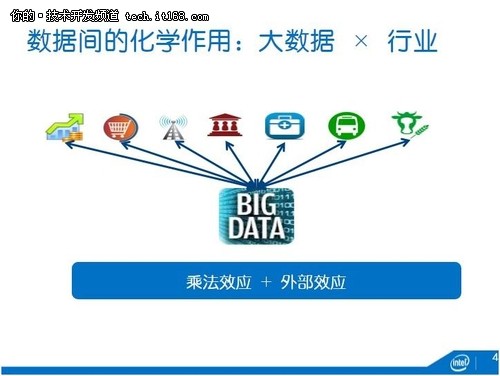
所以,我們希望數據能夠像“金風玉露一相逢,便產生化學作用”。馬化騰先生提出了一個internet+,internet可以幫助各行各業,我們也杜撰了一個大數據X,大數據乘以各行各業。如下圖所示,乘法效應之外,數據有個非常奇妙的效應叫做外部效應(externality),比如這個數據對我沒用但對TA很有用,所謂我之毒藥彼之蜜糖。張家的數據和趙家的數據各自都沒啥活性,一碰到一起就發生化學作用。
在這張膠片上列出了一些數據跨行業融合的案例。比如說:
金融數據跟電商數據碰撞在一起,就產生了像小微貸款那樣的互聯網金融;
電信數據跟政府數據碰在一起,可以產生人口統計學方面的價值,幫助城市規劃人們居住、工作、娛樂的場所;
金融數據跟醫學數據碰在一起,麥肯錫列舉了很多應用,比如說可以發現騙保;
物流數據和電商數據湊一塊,可以了解各個經濟子領域的運行情況;
物流數據跟金融數據放在一起,就產生了供應鏈金融;
金融數據跟農業數據也能夠發生一些化學作用,Google analytics出來的幾個人,利用美國開放氣象數據,能夠在每一塊農田上面建立微氣象模型,預測災害,幫助農民保險和理賠。
▲
所以,要走數據開放之路,讓不同領域的數據真正流動起來、融合起來,才能釋放大數據的價值。
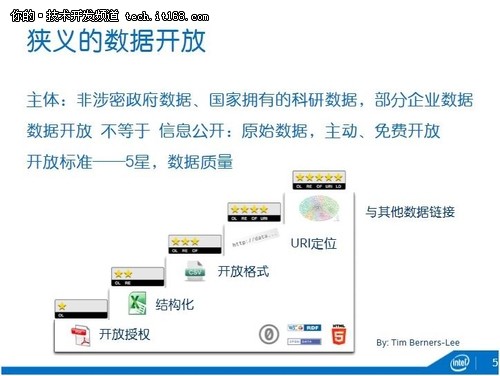
先來看狹義的數據開放(下一張slide)。數據開放的主體首先是政府和科研機構,把非涉密的政府數據,以及國家拿納稅人的錢做的一些科研數據開放出來。現在也有一些企業愿意開放數據,像Netflix、一些電信運營商,來幫助他們的數據價值化,建構生態系統。
數據開放不等于信息公開。首先,數據不等于信息,信息是從數據里面提煉出來的東西。我們希望,首先要開放原始的數據(raw data)。其次,它是一種主動和免費的開放,我們現在經常聽說要申請信息公開,那是被動的開放。
Tim Berners Lee提出了數據開放的五星標準,以保證數據質量:一星是開放授權的格式,比如說PDF;其次是結構化,把數據從文件變成了像excel這樣的表;三星是開放格式,如CSV;四星是能夠通過URI找到每一個數據項;五星,能夠跟其它數據鏈接,形成一個開放的數據圖譜。
▲
下面這張slide講數據開放的形態。現在主流的數據開放門戶,像data.dov或data.gov.uk,都基于開源軟件。Data.gov用WordPress做數據內容呈現,用CKAN做數據目錄,甚至data.gov自身也在github開源了。
英特爾在MIT的大數據科研中心也做了一種形態,叫Datahub,你看它的吉祥物很有趣,一半是大象,代表數據庫技術,一般是章魚,取自github的吉祥物章魚貓。它提供更多的功能,如:
-
易管理性,可以容易地檢索、合并和清洗數據;
-
像數據庫那樣的結構化數據服務;
-
安全方面,提供訪問控制,對數據共享進行管理;
-
最后,它可以在原地(in-situ)做可視化和分析,現在一般要把數據從開放門戶下載下來,然后在另外一個系統里做可視化和分析,這個能在原地做。
-

▲
數據開放當中會碰到很多問題(下圖),首先是數據權屬的問題,這個數據屬于誰?屬于采集人,還是屬于生產人,還是屬于被觀察的客體?如果發生一些特別情況的話,它的擁有權是不是會出現一些分割或者轉移?比如說離婚了,比如說人死了,這樣數據資產怎么轉移?
另外就是敏感數據的界定,數據里面有很多敏感的部分,比如說歐洲GPS位置信息的數據是屬于敏感數據,在日本又不屬于敏感數據。所以,這需要一個法律的界定。
針對這些敏感數據要做數據的脫敏,脫敏最初級的一種做法就是去標識化,但是去標識化一定要去的徹底。美國做過一個研究,如果把名字、地址什么都拿掉,但你只要剩下三個信息:郵政編碼、性別、生日,只要根據這三個信息,你還是有60-90%的可能性,把人還原出來。
當然,你即使是去標識去的很徹底,你還是要防止重新標識化(re-identification),比如你可以通過多數據源來重新進行標識。美國在線曾經開放了匿名的搜索信息,但是有人把這個信息跟美國的選舉人登記信息一匹配,就把人找出來了。Netflix也是一樣,他開放了匿名的評論以及打分的信息,但是有人把它跟國際電影數據庫IMDB匹配,結果把一個有同性戀傾向的人識別了出來,被告了。另外一種重新標識的可能性是基于統計,比如根據兩個打分再加上一定的時間范圍,還是有接近70%的可能性能夠把這個人找出來。
防止隱私攻擊的匿名化技術,比較典型的如k-anonymity和L-diversity等等,但還是有隱私攻擊的可能,特別在敏感屬性不夠多樣化,或攻擊者具有背景知識時。最好的一種技術叫差分隱私(differential privacy),把噪聲加入到數據集中、但仍保持它的一些統計屬性,英特爾支持普林斯頓大學做了這樣的研究,現在試圖在運營商開放數據中應用。

▲
以上是狹義的數據開放,廣義的數據開放還有數據的共享及交易(下圖),比如點對點進行數據共享或在多邊平臺上做數據交易。
馬克思說生產資料所有制是經濟的基礎,但是現在大家可以發現,生產資料的租賃制變成了一種主流(參考《Lean Startup》),在數據的場景下,我不一定擁有數據,甚至不用整個數據集,但可以租賃。租賃的過程中要保證數據的權利。
首先,我可以做到數據給你用,但不可以給你看見。姚期智老先生82年提了個“millionaires’ dilemma”問題,兩個百萬富翁比富,但誰都不愿意說出自己有多少錢。這就是典型的“可用但不可見”場景。在實際生活中的例子很多,我一直用的一個例子是:美國國土安全部有恐怖分子名單(數據1),航空公司有乘客飛行記錄(數據2),國土安全部去問航空公司要乘客飛行記錄,航空公司不給,因為隱私,他反過來問國土安全部要恐怖分子名單,也不行,因為是國家機密。雙方都有發現恐怖分子的意愿,但都不一樣給出數據,有沒有辦法讓數據1和數據2放一起掃一下,但又保障數據安全呢?
其次,在數據使用過程中要有審計。萬一那個掃描程序偷偷把數據藏起來送回去怎么辦?
再者,需要數據定價機制,雙方數據的價值一定不對等,產生的洞察對各方的用途也不一樣,因此要有個定價機制,比大鍋飯式的數據共享更有激勵性。
從點對點的共享,最后要走到多邊的數據交易,從一對多的數據服務到多對多的數據市場,再到數據交易所,如果說現在的數據市場更多是對數據集進行買賣的話,而這個數據交易所是一個基于市場進行價值發現和定價的,像股票交易所那樣的、小批量、高頻率的數據交易。

▲
我們支持了不少研究來實現剛才說的這些功能,比如說可用而不可見。案例一是通過加密數據庫CryptDB/Monomi(下圖),這也是我們支持麻省理工學院做的一個技術。在數據擁有方甲方這邊的數據庫是完全加密的,這事實上也防止了現在出現的很多數據泄露問題,大家已經聽到,比如說某互聯網服務提供商的員工偷偷把數據拿出來賣,你的數據一旦加密了他拿出來也沒用。其次,這個加密數據庫可以運行乙方的普通SQL程序。因為它采用了同態加密技術和洋蔥加密法,SQL的一些語義在密文上也可以執行。
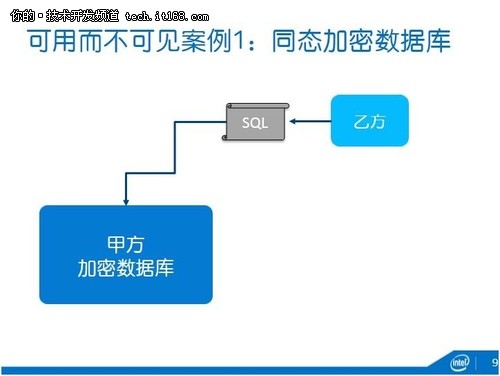
▲
針對類似百萬富翁窘境,我們針對此做了另一種可用但不可見的技術,叫做數據咖啡館(下圖)。大家知道咖啡館是讓人和人進行思想碰撞的地方(順便推薦Steven Johnson的TED演講, where good ideas come from),我們這個數據咖啡館就是讓數據和數據能夠碰撞,產生新的價值。
比如兩個電商一個是賣衣服的一個是賣化妝品的,他們對于客戶的洞察都是相對有限的,如果說兩邊的數據放在一起做一次分析,那么就能夠獲得全面的用戶畫像。再如,癌癥研究,癌癥是一類長尾病癥,有太多的基因突變,每一個研究機構的基因組樣本都相對有限,這在某種程度上解釋了為什么過去50年癌癥的治愈率僅僅提升了8%。那么,多個研究機構的數據在咖啡館碰一碰,也能夠加速癌癥的研究。
在咖啡館的底層是一個多方安全計算的技術,基于英特爾跟伯克利的一個聯合研究。在上面是安全、可信的Spark,基于“data lineage”的使用審計,還有就是根據各方數據對結果的貢獻進行定價。有可能一家電商是新的,他還沒有太多的數據,這就碰到一個機器學習冷啟動的問題,那么我可以運用另外一家電商數據,做所謂的transfer learning,幫助他解決這個冷啟動的問題。很顯然,另外那家電商的數據價值就應該更高。
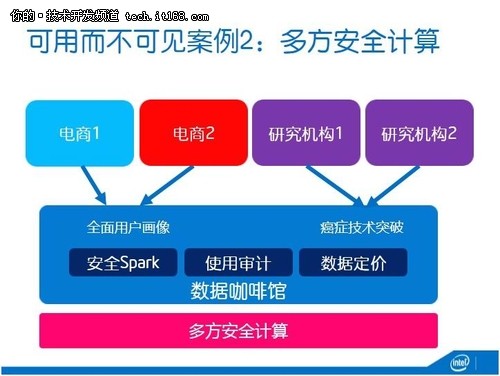
▲
把數據定價拔高一點。我們數據社會的經濟基礎是什么?一定要有一些基本規律。大家知道,互聯網經濟有個基本規律叫Metcalf定律,應該是Gilder提出的,為致敬以太網發明人Metcalf而命名。它是說一個網絡的價值是跟你的節點數平方成正比。它的另一種表述是網絡效應或網絡外部性:隨著網絡使用者的不斷增多,每一個使用者從中獲得的價值不斷增加,但使用費用則不斷下降。這奠定了互聯網的需求方規模經濟的商業模式,后面的所謂“邊際成本趨向于零”、“邊際效益遞增”、“正向反饋”、“馬太效應”和“贏家通吃”等皆由此衍生而出。而如今互聯網公司的通用估值方法,股票價值折現分析法或DEVA估值法,也是90年代一些分析師基于此提出的:一個網絡公司的價值是跟他的用戶數平方成正比的。這種巴菲特不能理解、但又符合規律的估值方法幫助年年虧損的互聯網公司融到了大筆資金,也解釋了Facebook上市前能夠估值千億美元,不是因為它的營業額(40多億)或利潤(不到10億),而是因為它的8億用戶量。Google有個首席經濟學家Hal Varian,這哥們在90年代末寫了一本書,名字大致是信息時代的規則,當時賣得比KK的《新經濟、新規則》好很多(現在KK的這本書賣得很好了,不同時代的口味是不一樣)。Varian的團隊專門研究互聯網和經濟的交叉學科。
那么,大數據時代的Metcalf定律是什么呢?
我們也不知道,一來從實踐中摸索,二來有意識地跟經濟界做思想碰撞。

▲
比如(下圖),數據在公開市場交易的時候,該怎么定價?是根據市場價值發現機制來定價?還是根據數據的種類來定價?還是根據數據訪問API的調用次數來定價?
在點對點的時候,各方的數據對于智慧產生的貢獻不一樣,也需要定價。
現在企業的資產中有一部分無形資產是數據資產。那么,這怎么來提升我們企業的估值?這部分數據資產價值幾何?現在也有一些很好的研究,比如consumption based model。
個人數據也需要定價,大家知道現在個人數據幾乎是免費的,我們為了獲得互聯網服務提供商的免費服務,把數據免費給了服務提供商。但是,現在國外對于小數據、對于個人數據有價,已經開始覺醒了。有一個初創公司愿意給消費者一部分錢,你把你的Facebook數據、推特數據、銀行交易數據給這家公司,他來價值化(比如找廣告商)。現在的定價很簡單,女性一個月14美金(女性的消費能力強啊),男性一個月8美金,未來該怎么定價也是個很有意思的話題。
在共享交易當中也注意偽造的數據或劣質的數據,有人在共享的時候把一些假的數據、雜質數據放進去怎么辦?這也是很有意思的問題,而且很現實。Snowdon的文件解釋英國情報機構GCHQ就很善于在網絡數據中摻假,改變網絡民意或熱點,創造虛假流量。

▲
前面說的是數據的開放,下面很快說一下另外兩種開放。
一是大數據基礎設施的開放(下圖),現在有的是有大數據思維的人,但他們很捉急,玩不起、玩不會大數據,他不懂怎么去存儲、怎么處理這些大數據,這就需要云計算。如果說數據開放是Data as a Service,基礎設施的開放還是傳統的Platform as a Service,比如Amazon AWS里有MapReduce,Google有Big Query。這些大數據的基礎處理和分析平臺可以來降低數據思維者的門檻,來釋放他們的創造力。
比如decide.com,每天爬幾十萬的數據,對價格信息(結構化的和非結構化的)進行分析,然后告訴你買什么牌子、什么時候買最好。只有四個PhD搞算法,其他的靠AWS。
另一家公司Prismatic,也利用了AWS,這是一家做個性化閱讀推薦的,我專門研究過它的計算圖、存儲和高性能庫,用LISP的一個變種Clojure寫的,非常漂亮,真正做技術的只有三個學生。
所以當這些基礎設施社會化以后,大數據思維者的春天很快就要到來。

▲
最后一種開放是價值提取能力的開放(下圖)。現在的模式一般是一大一小或一對多。比如Tesco和Dunnhumby,后者剛開始是很小的公司,傍上了Tesco,給它做客戶忠誠度計劃,一做就做了幾十年,這樣的長期的戰略合作優于短期的數據分析服務,決策更注重長期性。當然,Dunnhumby現在已經不是小公司了,Tesco控股,也為其他大公司提供數據分析服務。沃爾瑪跟另外一家小公司合作做數據分析,最后他把這家小公司買下來了,成了它的Walmart Labs。
一對多的模式,典型的是Palantir,Peter Thiel和斯坦福的幾個教授搞的公司,目前還是私有的,但估值近百億了,它很擅長給各類政府和金融機構提供數據價值提取服務。
真正把這種能力開放的是Kaggle,它的雙邊,一邊是10萬多的分析師,另一邊是需求方企業,企業在Kaggle上發標,分析師競標,獲得業務。這可能是真正解決長尾公司價值提取能力的辦法。這個如果跟我們的數據咖啡館結合,那就更好了。
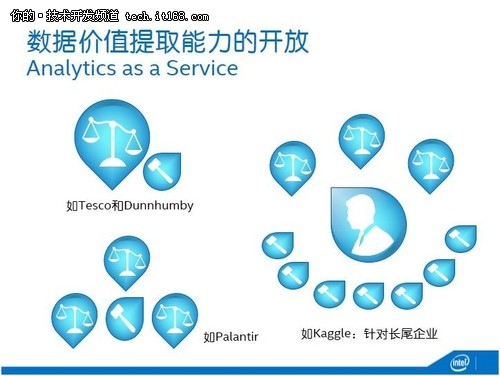
▲
好,今天就講到這,謝謝大家!

責任編輯:葉雨田
-

權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -

中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網
-
新基建助推 數據中心建設將迎爆發期
2020-06-16數據中心,能源互聯網,電力新基建 -

泛在電力物聯網建設下看電網企業數據變現之路
2019-11-12泛在電力物聯網 -

泛在電力物聯網建設典型實踐案例
2019-10-15泛在電力物聯網案例



-
權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -
中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業發展
-
探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網 -

5G新基建助力智能電網發展
2020-06-125G,智能電網,配電網 -

從智能電網到智能城市