融合多源數據的智能配用電多時間尺度數據分析技術
摘要:隨著分布式發電、儲能和需求側響應負荷的不斷發展,傳統的被動型用電網正在逐步演變為具有主動調節能力的主動配電網。為了充分發揮主動配電網的主動調節能力,需要在配用電網中安裝智能電表、遠程測控終端和配電網同步測量等數據采集裝置,建設配電、用電、客服、營銷等信息管理系統。這些數據采集裝置和系統的建設,在配用電領域產生了大量的數據。文章在討論智能配用電大數據來源、生命周期及數據特征的基礎上,從數據集成平臺、智能電網統一數據模型、多源數據在線、數據分析算法庫、用戶畫像、機器學習算法等角度分析了智能配用電大數據分析的關鍵技術,然后提出了智能配用電大數據分析在電網運行、社會服務和用戶服務方面的典型應用。
0、引言
隨著分布式發電、儲能和需求側響應負荷在配用電網中接入比例的不斷提高,傳統的被動型用電網正在逐步演變為具有主動調節能力的主動配電網。為了充分發揮主動配電網的主動調節能力,需要在配用電網中安裝智能電表、遠程測控終端和配電網同步測量等數據采集裝置,建設配電、用電、客服、營銷等信息管理系統。這些數據采集裝置和系統的大規模建設,使得電網公司首次獲得了數以億計電力用戶多時間尺度的在線用電信息,以及數以萬計的電網運行狀態監控信息。這些信息使我們獲得了前所未有的可以從時間和空間多個角度,對用戶實際用電過程和與電網密切互動過程進行全方位分析的大數據。
近年來快速發展起來的大數據分析技術具有全數據分析、規律性分析、跨領域分析以及快速性分析的特點,為充分利用智能配用電系統中的多源數據,進行多時間尺度分析提供了強大的技術手段。
區別于單一功能的電網公司業務部門的信息化系統,智能配用電大數據分析系統的研究目標是將多個信息化信息系統中的數據進行融合,解決依賴單一信息化系統解決不了或者解決不好的問題。本文首先討論智能配用電大數據分析系統的數據源和生命周期;然后分析智能配用電系統中的數據在時間和空間中的相互關系、以及基本特征,據此分析出融合智能配用電多源數據所必須解決的關鍵技術;從數據集成平臺、智能電網統一數據模型、多源數據在線、數據分析算法庫、用戶畫像、機器學習算法等角度分析了智能配用電大數據分析的關鍵技術,最后提出了智能配用電大數據分析在電網運行、社會服務和用戶服務方面的典型應用。
1、智能配用電大數據分析的數據源與生命周期
1.1智能配用電大數據的來源
根據來源的不同,可以將智能配用電大數據分為電力企業內部數據和外部數據。電力企業內部數據產生于配電管理/配電SCADA系統、生產管理系統、用電信息采集系統、電力營銷系統、客戶服務信息系統等。這些數據包括靜態數據、實時數據和歷史數據,其中靜態數據包括電網設備模型參數、線路拓撲結構、電力用戶資料數據等,實時數據包括遙信、遙測數據,如設備運行狀態、電量計量等。外部數據來源于地理信息系統、氣象預報系統、互聯網數據、公共服務部門數據、社會經濟數據等。這些數據也為電網運行、管理、服務等提供支持。
1.2智能配用電大數據的生命周期
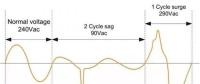
數據的采樣頻率與生命周期也各不同,從微秒級、分鐘級、小時級,一直到年度級。不同數據的數據源與生命周期見圖1。配電PMU數據的數據采樣頻率為每10~20ms一次,可用于毫秒級的快速實時分析,主要應用于配電自動化系統的故障隔離、保護和控制;SCADA數據的采樣頻率為4~6s一次,可以首先存儲在實時數據庫中,進行秒級的實時分析,主要應用于配電管理系統的故障診斷、隔離和恢復、配電網狀態估計及分布式電源優化和需求側管理等;智能電表數據的采樣頻率為15min一次,可用于分鐘級的在線分析,主要應用于在線大數據分析系統的數據質量、電能質量、網損的在線分析,以及多源數據融合狀態估計,用電行為和負荷特性微增在線分析等,通過數據抽取、轉換與載入為后續分析提供基礎數據;智能電表數據與氣象數據和其他數據融合可為從每日到多年的交互式大數據分析系統服務,提供用戶、配變、變電站、系統多時間尺度數據分析等功能,以及系統用電行為分析,設備負載率分析,非常規用電行為分析和精準營銷等功能。

圖1 智能配用電分析數據源與生命周期
2、智能配用電大數據分析的關鍵技術
智能配用電大數據分析的關鍵技術共有4類,詳見圖2。第一類關鍵技術為數據集成平臺與數據模型技術研究,主要用于集成不同數據源的數據,通過SPARK分布式內存架構并行完成數據清洗和數據轉換等,并建立基于數據倉庫的統一數據模型;第二類關鍵技術為智能配用電在線分析技術,基于SPARK的內存并行流處理技術處理新進入數據分析系統的數據,并且提供智能電表數據的數據質量和供電質量分析,以及用戶的用電行為和靜態負荷特性分析等功能,融合智能電表數據與配電SCADA和PUM數據來建立配電網狀態估計算法;第三類關鍵技術為智能配用電交互式分析技術,主要基于K系列數據挖掘算法將時間序列的數據分類,并提供基于智能電表數據的日負荷形狀和用電行為分析、配變負載率分析、大型電器用電行為分析、低壓電網拓撲等分析,融合智能電表和SCADA數據的變電站網損分析,以及基于PMU數據的動態和靜態負荷特性辨識;第四類關鍵技術為時空融合的配用電大數據分析應用,主要基于多時空、多時間尺度數據分析,進行變電站、配變數據等數據分析、負荷模型參數辨識等應用,基于用戶智能電表的用戶畫像功能,和基于地理信息的用電行為分析、大型用電器行為分析、以及精準營銷的應用。

圖2 智能配用電大數據分析的關鍵技術
2.1數據集成管理平臺架構與統一數據模型技術
智能配用電大數據的第一個關鍵技術是數據集成管理平臺架構與統一數據模型技術。集成管理平臺將若干分散的數據源中的數據,邏輯地或物理地集成到一個統一的數據集合,即統一數據模型中,為后續分析存儲一系列面向主題的、集成的、相對穩定的、反應歷史變化的數據集合,從而為系統提供全面的數據共享,解決電力企業內部各系統間的數據冗余和信息孤島的問題。
配用電數據集成與管理平臺的數據源包括內部數據和外部數據。內部數據包括智能電表數據、配電自動化/SCADA數據、配電網線路信息、設備運行信息、用戶信息、空間位置信息等;外部數據包括地理信息數據、氣象數據、人口數據等。這些數據根據其特性可以存儲在傳統數據倉庫中,也可以存儲在NoSQL數據庫中或是圖數據庫中。數據集成的核心任務是要將互相關聯的分布式異構數據源集成到一起,使用戶能夠以透明的方式訪問這些數據源。
配用電數據基礎與管理平臺根據智能電網統一數據模型SGDM,按照從上至下的設計理念,將來自多個數據源的數據按照資產信息、網絡拓撲模型、用戶信息和外部數據進行有機整合,覆蓋網絡運行、賬戶管理、資產管理、客戶管理、停電管理、工作管理和天氣模型等業務領域,結合包括KPI在內的智能電網大數據分析挖掘需求,針對支持電力公司的運營和發展、分析用戶行為與服務優化、為政府與社會提供決策咨詢與支持3類應用,設計8個業務域,49個主題域,定義包括實體及其關系在內的邏輯模型,并依據第三范式原則優化物理模型。
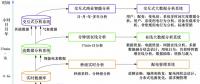
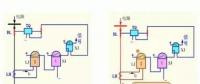
針對配用電數據的來源多重性、實時交互性、時間相關性和多尺度性,見圖3,SPARK中的彈性分布式數據集(RDDs)運用高效的數據共享概念和類似于MapReduce的操作方式,集成地理信息等靜態數據,并通過通過離散流將動態流數據集成,在一段時間周期上進行一系列確定性的批處理計算。在數據倉庫中分層處理不同的數據,其中包含基礎數據層、數據分析層和核心展示層。在基礎數據層采用標準化的公共信息模型(common information model,CIM),用于描述能量管理系統中主要數據對象,是面向電力生產交易全環節相關對象及其關系的面向對象建模方法。在數據分析層,采用包括規則引擎、報表工具、挖掘工具、可視化互動分析工具等軟件,為大數據實驗室未來的各類專題研究提供數據分析手段。在核心展示層安裝地理信息,按照從配電系統到變電站到配變最后到每個用戶逐級展示負荷特性、有功功率和無功功率、電能質量和負載等信息。

圖3 數據集成管理平臺架構與統一數據模型技術

責任編輯:電朵云